One of the most confusing aspects of SEO is learning how to write a robots.txt file to ensure that search engines crawl your site in an efficient manner and only index content that you want to be found in search results. This guide is intended to make creating a robots.txt file for your website a more comprehensible task.
This guide also focuses on common robots.txt optimizations for WordPress websites. The WordPress CMS accounts for nearly 20% of all websites, making it the most common CMS in the world. However, much of this advice can be applied to another CMS as long as the differing URL structures are taken into account.

What is a Robots.txt File? Why is it Important?
The robots.txt file is simply a “.txt” file that is uploaded to your root folder (usually via FTP) that contains a list of crawl directives that you provide to search engines when they visit your website for crawling. View mine here if you aren’t familiar with what it looks like. It’s pretty damn boring.
Accessing your website’s robots.txt file is the first step in a search bot’s crawling process, and optimizing your robots.txt file serves as your first line of defense in ensuring that search engine bots spend their time wisely when crawling your website. It’s especially important for large websites where a search bot’s crawl budget may not allow for a full crawl of the website.
The Robots.txt User Agent
The rules within a robots.txt file can be directed at either all crawlers or specific crawlers, and the User-agent protocol is used to specify the crawler that your rules pertain to. It should be listed above your rules (for each user-agent).
Using the User-Agent: * protocol will apply the rules to all crawlers, however, here are other common user-agents that you may need to use when writing rules for specific crawlers in your robots.txt file. You can find a more complete list here.
- Google (General) – User-agent: Googlebot
- Google (Image) – User-agent: Googlebot-Image
- Google (Mobile) – User-agent: Googlebot-Mobile
- Google (News) – User-agent: Googlebot-News
- Google (Video) – User-agent: Googlebot-Video
- Bing (General) – User-agent: Bingbot
- Bing (General) – User-agent: msnbot
- Bing (Images & Video) – User-agent: msnbot-media
- Yahoo! – User-agent: slurp
The Robots.txt Disallow Rule
The main rule involved in robots.txt file optimization is the “disallow” rule. It instructs search engines to NOT crawl a specific URL, a specific folder or a collection of URLs determined by a query string rule (often a wildcard rule using an asterisk). This will also result in URLs not being indexed in search engines (or being “suppressed” if they’re already indexed).
The disallow rule should be used with relative path URLs, and can only control a search bot’s crawling behavior on your own website. It is formatted as such:
Disallow: rule-goes-here
The “rule-goes-here” portion should be replaced with whatever rule you want to put into place. Again, it can be a specific URL, specific subfolder or a collection of URLs determined by a query string rule. Here are some examples of each:
Disallowing a Specific URL
The following rule will instruct search engines not to crawl a URL at http://www.domain.com/specific-url-here/.
Disallow: /specific-url-here/
Disallowing a Specific Subfolder
The following rule will instruct search engines not to crawl any URLs in the subfolder located at http://www.domain.com/subfolder/.
Disallow: /subfolder/
Disallowing URLs by Query String
The following rule will instruct search engines not to crawl any URLs that begin with http://www.domain.com/confirmation, no matter what characters come after this initial part of the URL. This can be helpful if you have a number of URLs that are built with a similar structure, but you don’t want search engines to crawl or index them (i.e. – confirmation pages for email acquisition forms).
Disallow: /confirmation*
Note: You must be careful with this rule, as you can unintentionally disallow crawl of important pages that you actually want search engines to crawl and index.
Common WordPress Subfolders & Query Strings to Disallow
There’s a common set of subfolders that are native to the WordPress CMS which you’ll want to limit search engines from crawling. Here is a quick list of folders to use a “Disallow” rule for:
- WordPress Admin – /wp-admin/
- WordPress Includes – /wp-includes/
- WordPress Content – /wp-content/
- Internal Search Results – /?s=*
For WordPress sites, however, it’s important to “allow” your /wp-content/uploads/ subfolder to be crawled by search engines so that your images can be indexed. Thus, you’ll want a rule such as the following:
Allow: /wp-content/uploads/
The Robots.txt File “Allow” Rule
This rule became much more popular once Google announced that it wants to be able to crawl CSS and javascript in order to render the page like a user would see it. A simple approach would be to add the following rules to the User-agent: Googlebot section of your robots.txt file.
User-agent: Googlebot Allow: *.js* Allow: *.css*
However, what I’ve found is that Google doesn’t always respect these “Allow” rules if you have CSS and javascript files located in various subfolders.

The following WordPress subfolders should typically be disallowed from crawling, but might have javascript and CSS files within them that Google cannot access unless you provide specific “allow’ commands for them:
- /wp-admin/
- /wp-includes/
- /wp-content/themes/
- /wp-content/plugins/
In order to unblock javascript and CSS files within these subfolders, in addition to any javascript and CSS files not included in these subfolders, the following rules are needed:
User-agent: Googlebot Allow: /*.js* Allow: /*.css* Allow: /wp-content/*.js* Allow: /wp-content/*.css* Allow: /wp-includes/*.js* Allow: /wp-includes/*.css* Allow: /wp-content/plugins/*.css* Allow: /wp-content/plugins/*.js* Allow: /wp-content/themes/*.css* Allow: /wp-content/themes/*.js*
The “NoIndex” Rule for Robots.txt
Google has stated that they may respect a “Nondex” rule in your robots.txt file, per this Google Webmaster Hangout with John Mueller, a well-known Google Webmaster Trends Analyst.
However, John Mueller stated a month later on Twitter that he doesn’t advise using the “NOINDEX” rule in a robots.txt file.
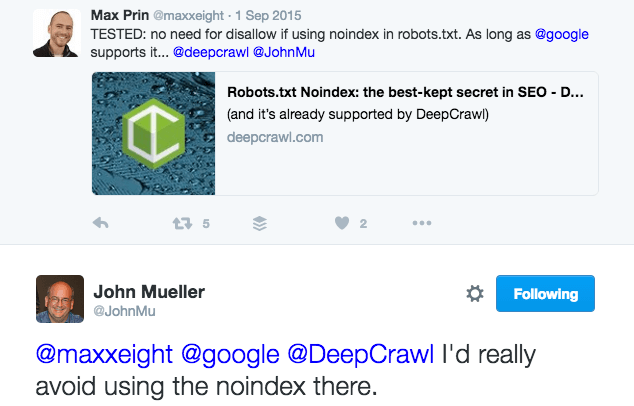
So, using this rule is up to you. It doesn’t replace the best practice of controlling indexation with meta robots and X-robots tags, however it could be helpful (only with Google) in a pinch if technical limitations leave it as the last resort.
The rule is simple to implement. Here are a few examples:
NOINDEX: /xmlrpc.php* NOINDEX: /wp-includes/ NOINDEX: /cgi-bin* NOINDEX: */feed* NOINDEX: /tag* NOINDEX: /public_html*
The guys at Stone Temple Consulting conducted a test and determined that “Ultimately, the NoIndex directive in Robots.txt is pretty effective.” I’ve had good success with using the NoIndex rule in my robots.txt file to get some straggler /tag/ pages out of Google’s index as well. So, feel free to use this rule to further optimize your robots.txt file. However, consider that it only works for Google, who may choose to not respect it at any point in time.
Linking to Your XML Sitemap in the Robots.txt File
Search engines also will look for an XML sitemap in your robots.txt file. If you have more than one XML sitemap, such as a video XML sitemap in addition to your main XML sitemap, then you’ll want to link both here. The XML sitemaps should be linked in your robots.txt file as follows (typically at the bottom of your sitemap):
Sitemap: http://www.domain.com/sitemap_index.xml Sitemap: http://www.domain.com/video-sitemap.xml
Testing Robots.txt Rules in Google Search Console
Google provides two tools in Google Search Console that are excellent for testing your robots.txt file rules to ensure that they’re being respected and that you’re properly unblocking javascript, CSS and other important files that Google needs to crawl in order to render the page like a user sees it.
Fetch as Google
The Fetch as Google tool in Google is a great starting point to discover any blocked resources that Google cannot crawl and render due to your robots.txt file rules. Commonly reported issues are javascript files, CSS files and blocked images.
When using this tool, take note of any blocked resources for testing changes to your robots.txt file rules. You want to either have no blocked resources, or only external blocked resources (which you cannot control). The following screenshot shows that only two external resources in my robots.txt file were not crawlable by Google. That’s good.

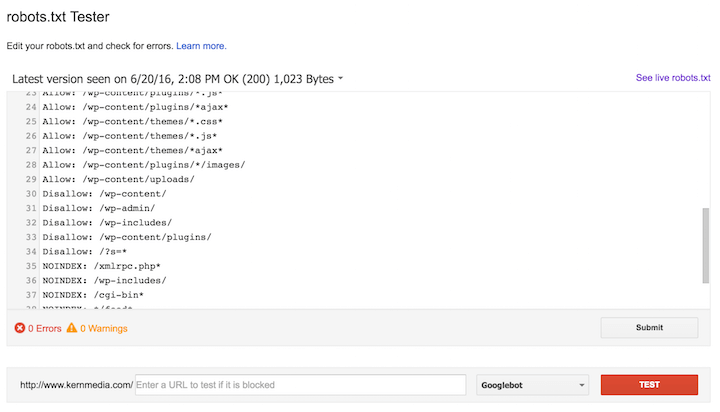
Robots.txt Tester
Once you’ve determined any blocked resources, use the Robots.txt Tester tool to test implementation of new rules and determine if Googlebot is allowed to crawl them or not. Once your rules are finalized, add them to your live robots.txt file. Here’s what the tool looks like:
Additional Robots.txt Testing Tools
Thanks to Max Prin, Adam Audette and team at Merkle for creating this super awesome testing tool which allows you to test for blocked resources without having access to a website’s Google Search Console account. They’re even working on a special request (from yours truly) to allow for providing your own modified robots.txt file rules. This will allow us to see how Googlebot and other bots respond (in regards to blocked resources) to custom modifications to the rules prior to pushing them live (or for working on a development site). Definitely check it out.
Other Robots.txt Considerations
As someone who looks at Google’s search results every day, stays on top of technical SEO news, and helps clients with complicated technical SEO projects, I’ve come across some other issues related to robots.txt files that you might find helpful.
External Links to Disallowed URLs
If search engines find an external link to a URL that is disallowed via your robots.txt file, they might ignore your rule and crawl the page anyways due to the external signal. Here is what Google specifically states (source):
However, robots.txt Disallow does not guarantee that a page will not appear in results: Google may still decide, based on external information such as incoming links, that it is relevant. If you wish to explicitly block a page from being indexed, you should instead use the noindex robots meta tag or X-Robots-Tag HTTP header. In this case, you should not disallow the page in robots.txt, because the page must be crawled in order for the tag to be seen and obeyed.
That last sentence gives an extra tidbit of information. If you want a page to be removed from Google’s index, it needs to have a “noindex” meta robots tag in the <head> or an X-Robots-Tag in the HTTP header. Keep that in mind if you’re attempting to drop a bunch of low quality URLs from Google’s index and considering when you show disallow them via the robots.txt file.
Blocked Pages Still Appearing in Search Results
Pages on your site that were indexed in search engines prior to being disallowed via your robots.txt file may still appear in search engine indexes when conducting a site:domain.com query, yet have a message beneath them (such as in Google) that states “A description for this result is not available because of this site’s robots.txt”. The way to get them out is to unblock them in your robots.txt file (remove the “disallow” rule) and apply a “noindex” meta robots tag (or X-robots tag). Once you’ve confirmed that search engines have dropped out out of their index, you may block them again in your robots.txt file.
PPC Campaign Tracking URLs
Be careful when using wildcards in your “Disallow” rules when you are using campaign tracking URLs for paid search/social campaigns running with Google, Bing, Facebook, etc. The “ad bots” for these services will need to crawl your campaign tracking URLs, so you cannot block them.
For this reason, you will want to add a user-agent section for each “ad bot” that contains an “Allow” rule for each campaign tracking URL pattern (i.e. – Allow: /*?utm_medium=*).
Here are example rules for Google, Bing, and Facebook, using the ?utm_medium tracking code as an example.
User-agent: Adsbot-Google Allow: /*?utm_medium=*
User-agent: AdIdxBot Allow: /*?utm_medium=*
User-agent: Facebot Allow: /*?utm_medium=*
You can find more detail for each of these crawlers at the following links:
Filtered / Faceted URLs & Crawl Traps
If you have a large website with extended functionality (such as filtered and faceted URLs on category pages), then crawling your website with a search bot simulator such as Screaming Frog can help unveil some potential crawl traps for search engines.
After the crawl is complete, look for patterns of URLs that are obviously not quality pages that you want search engines to crawl and index. Write wildcard “Disallow” rules for them in your robots.txt file to prevent search engines from wasting their time crawling them (and not fully crawling the content that you actually want to be crawled and indexed). One of the most common traps that I’ve seen are filtered/faceted URLs.
Use My Optimized WordPress Robots.txt File
I welcome you to use my WordPress robots.txt file as a template. I’ve tested it numerous times to ensure that my rules are not blocking any important content, and also ensuring that Google can crawl my javascript or CSS files. Feel free to use it as a starting point, but be sure to use the Fetch as Google and Robots.txt Tester tools in Google Search Console to customize it for your particular website. You’ll also want to customize the XML sitemap URL (of course!).
Have questions? Leave them in the comments and I’ll be happy to answer them.